スポンサーリンク
アクセスログをBigQueryで分析する環境を構築してみました。その作業内容をメモしておきます。
アクセスログの出力するWebサーバーはNginx、BigQueryにそのアクセスログを転送するのには、fluentdを使用しました。
利用したサーバーのOSは、Ubuntu 16.04、作業の実施日は2017年5月6日です。
目次
- 1. やりたいこと
- 2. 手順の概要
- 3. Google BigQuery:プロジェクトを新規作成する
- 4. Google BigQuery:BigQuery APIを有効にする
- 5. Google BigQuery:無料トライアルの有効化(料金支払い関連)
- 6. Google BigQuery:「請求先アカウント」をプロジェクトに関連付ける
- 7. Google BigQuery:Google Cloud SDKをインストールする
- 8. Google BigQuery:Google Cloud SDKの利用
- 9. Google BigQuery:データセットを作成する(bq mkコマンド)
- 10. Google BigQuery:スキーマを用意する
- 11. Google BigQuery:テーブルを作成する
- 12. Nginx:アクセスログのフォーマットをLTSVにする
- 13. fluentd:fluent-plugin-bigqueryをインストールする
- 14. fluentd / Google BigQuery:サービスアカウントの作成
- 15. fluentd:fluentdの設定をする
- 16. fluentd:fluentdの再起動
- 17. 結果:BigQueryで分析可能に
- 18. 参考
- 19. 追記:ログファイルのファイルサイズが巨大化してしまってディスク容量を圧迫(+速度低下?/性能低下?)
スポンサーリンク
やりたいこと
やりたいことは、NginxのアクセスログをGoogle BigQueryに転送して、BigQuery上で分析すること、です。
手順の概要
最初に、Google BigQueryの利用開始手続きを行います。
そして、NginxのログをBigQueryに吸い上げるために、fluentdの設定を行います。
このときNginx側では、LTSV(Labeled TSV)形式でアクセスログを記録する設定(log_formatの定義)をしておきます。分析したいデータを自由にカスタマイズできるようにしています。Apacheでも別のウェブサーバーでも、LTSVで出しておけば、fluentdがパースしやすくおすすめです。
BigQuery、Nginx、fluentdの順に、作業・設定内容を紹介します。
Google BigQuery:プロジェクトを新規作成する
「Google Developers Console(https://console.developers.google.com/)」を開きます(Googleアカウントは取得済前提です)。
左上の既存のプロジェクト名の部分をクリックしてプロジェクト一覧を表示します。
新しいプロジェクトを作るために、「+」ボタンをクリックします。
すると、「新しいプロジェクト」画面が表示されるので、「プロジェクト名」を入力して(プロジェクトIDは自動設定されるが変更できないので、手動で設定しておいても良い)、「作成」をクリックします。
作成直後、どういうわけかプロジェクトの選択状態が完全に解除されて、一度「現在の選択内容ではページを表示できません。 このページを表示するには、プロジェクトを選択してください。」と表示されてしまったのですが、「選択」ボタンから、作ったばかりのプロジェクトを選択して、続きの設定を進めました(※選択時、「最近のプロジェクト」タブを「すべて」に切り替えないと、作ったばかりのプロジェクトが表示されませんでした。注意)。
Google BigQuery:BigQuery APIを有効にする
プロジェクトを選択すると、「有効なAPIがありません」状態から開始されるので、「+APIを有効にする」をクリックしました。
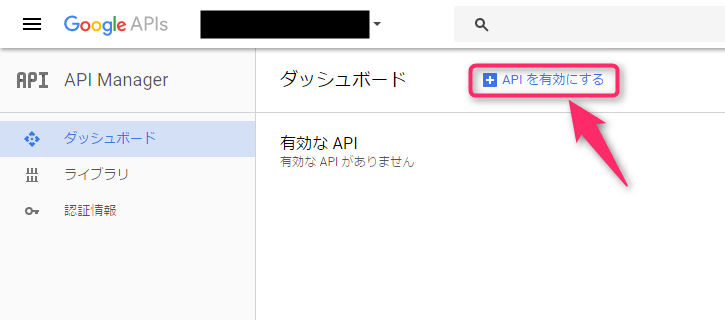
そして、Google APIの一覧の中から、「BigQuery API」をクリックします。
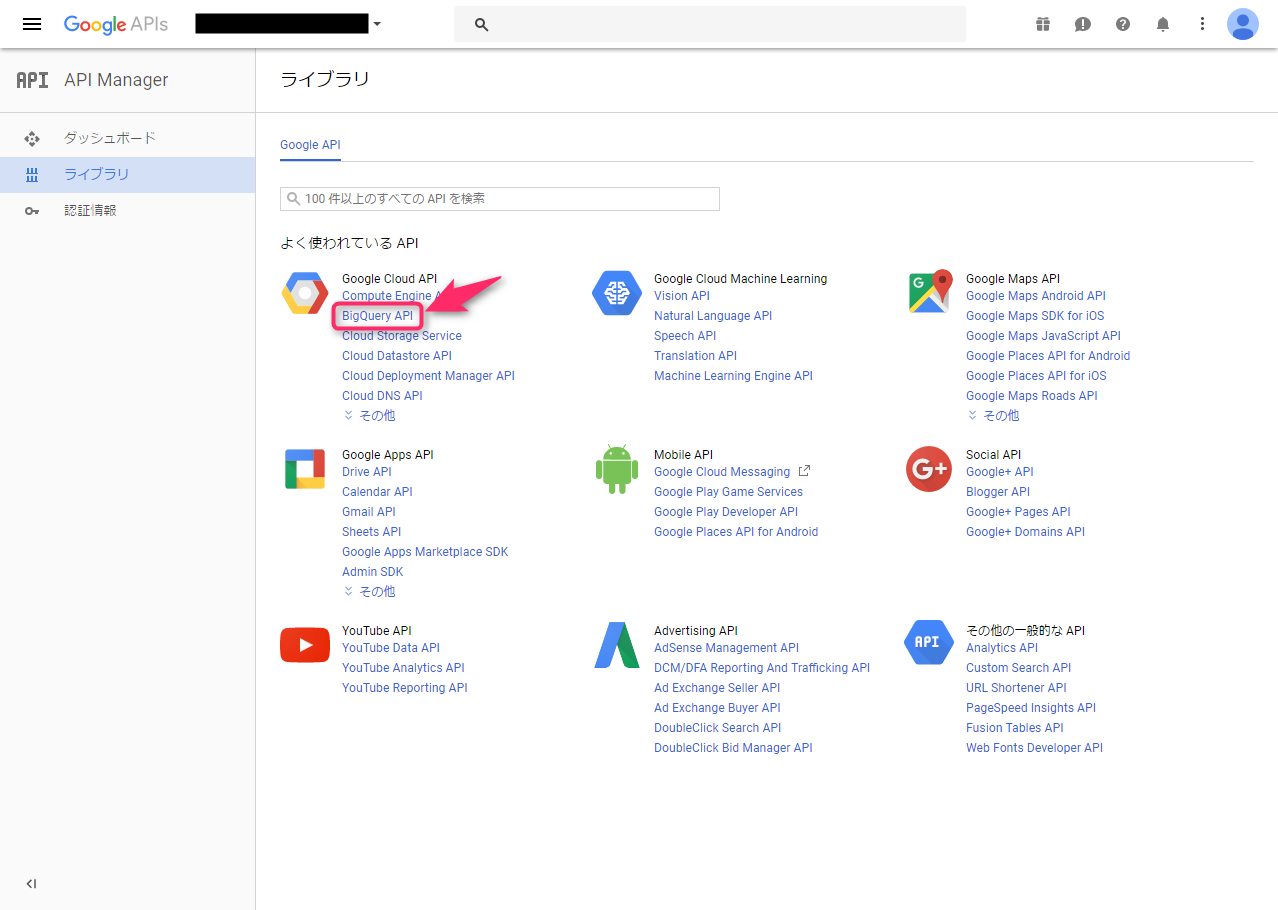
すると、Google APIの説明文が表示されて、「どこをクリックすれば先に進めるの??」と少し困惑しつつ、上部に表示された「有効にする」ボタンをクリックして、有効化します。
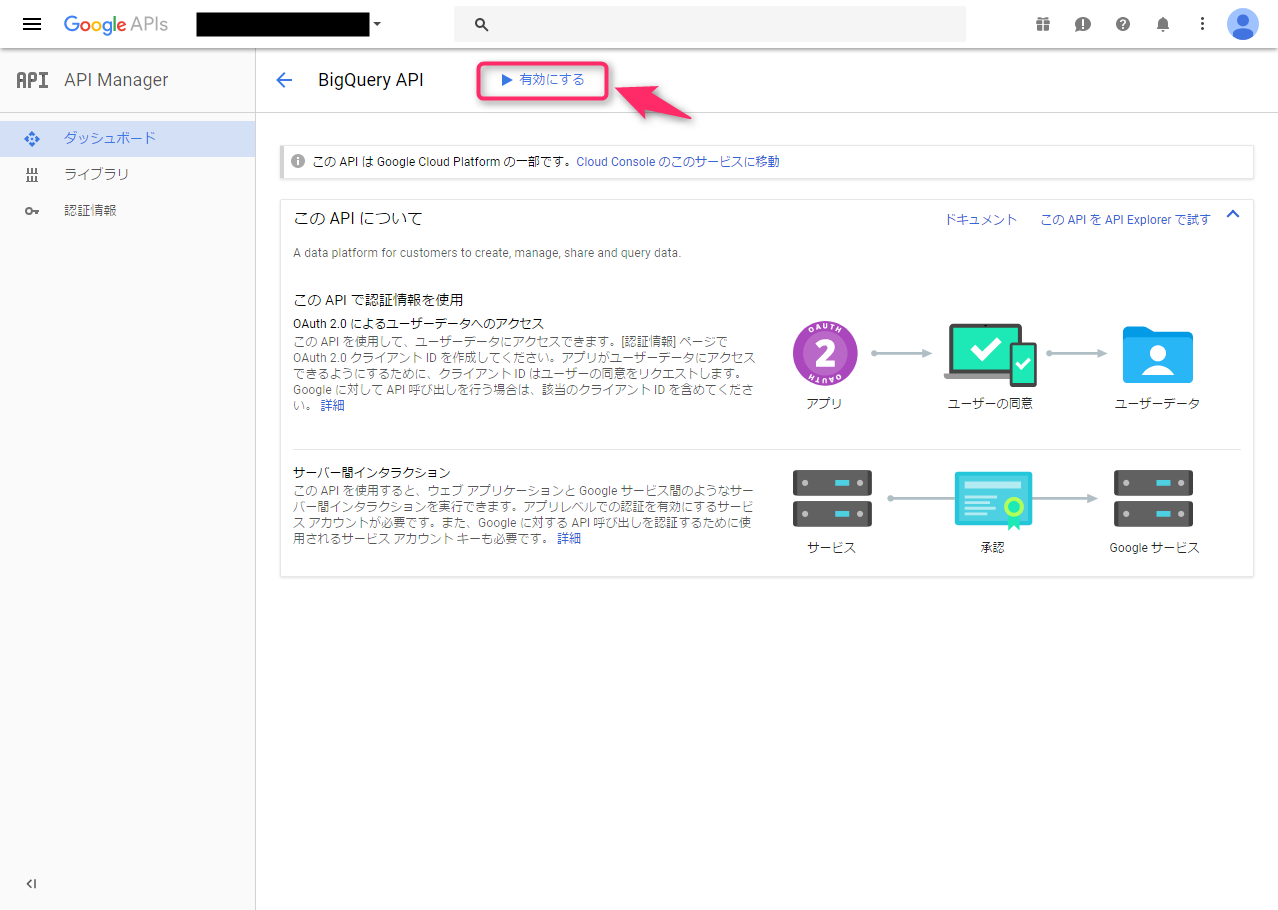
Google BigQuery:無料トライアルの有効化(料金支払い関連)
ここで、クレジットカードの登録をしようと思ったのですが、右上のプレゼントボタンから、無料トライアルの申込ができることが分かったので、そちらへ進むことにしました(無料トライアルが利用できない場合については後述。普通にクレカ登録でOKのはず)。
「無料トライアルに登録」をクリックします。
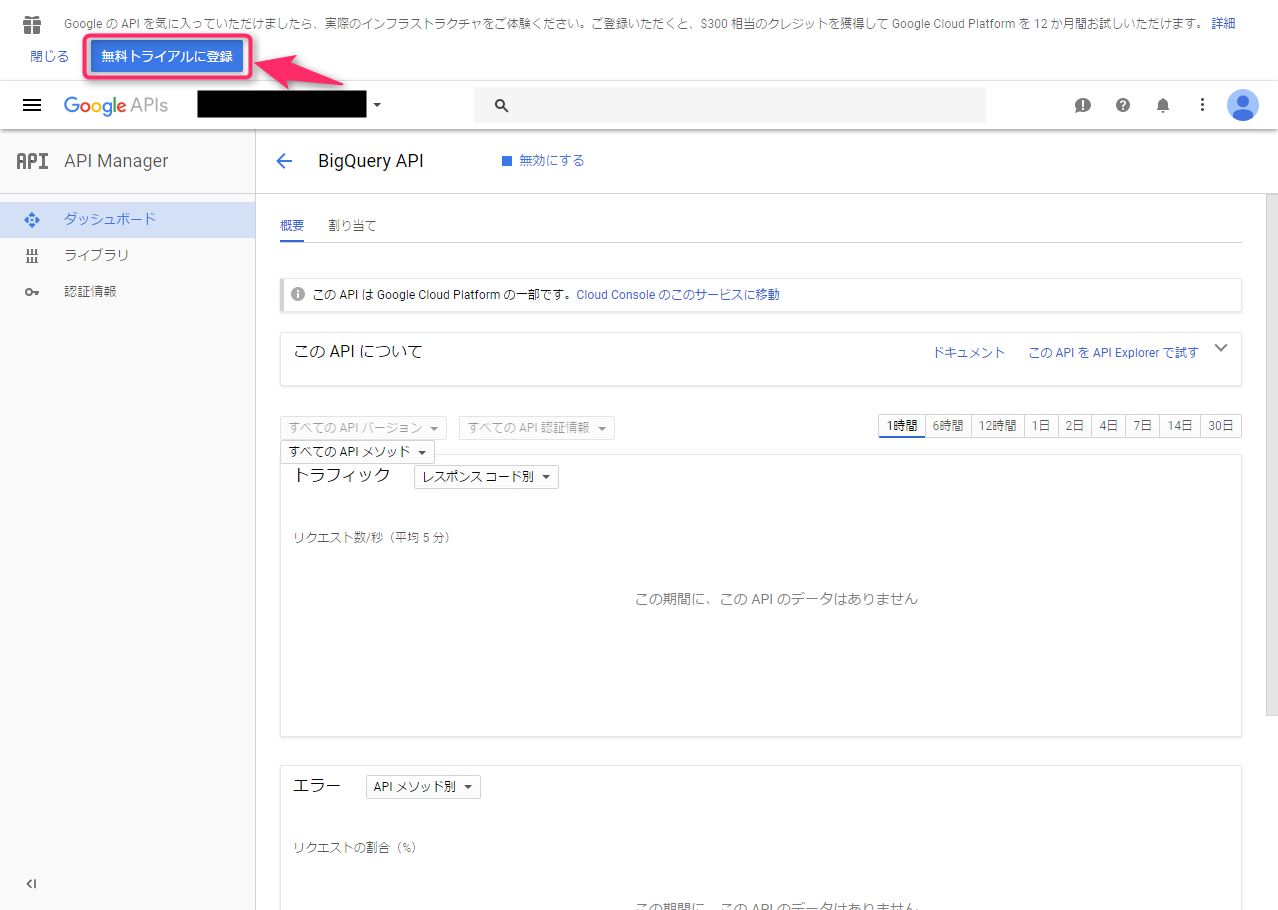
無料トライアル画面では、「国名」に日本、「新機能のお知らせ」「Google Cloud Platform 無料トライアルの利用規約」について「はい」を設定して、「同意して続行」をクリックしました。
次の画面で、「お支払のプロファイル」を確認して、「無料トライアルを開始」をクリックしました(※名前はアルファベット大文字でした。アカウントの種類「個人」の部分と、お支払のタイプの「毎月の自動支払い」の部分は変更できず)。
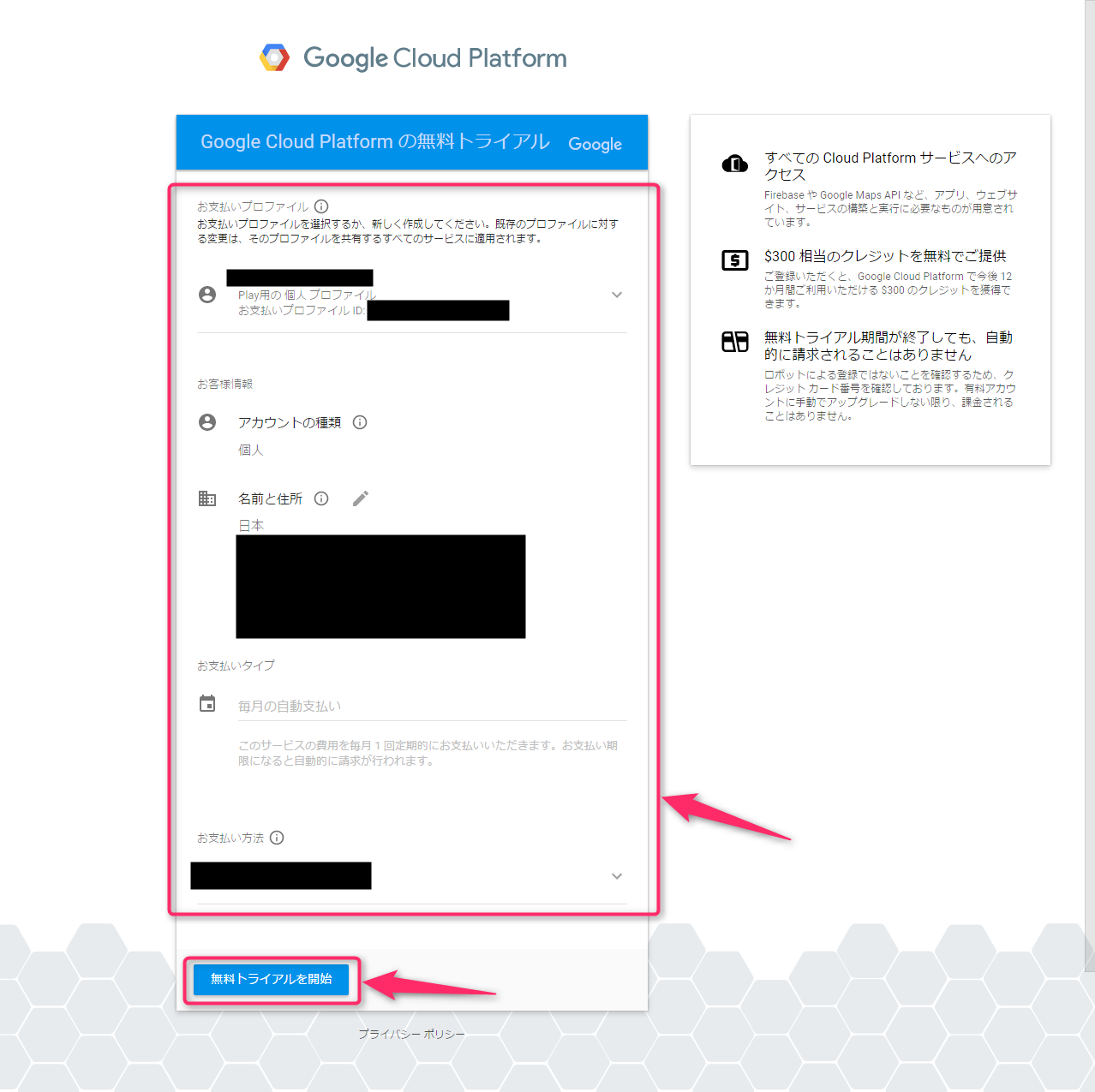
申込が終わると、Google Cloud Platformのコンソールが表示されて「ようこそ」画面が表示されるので、「OK」をクリックして閉じました。
Google BigQuery:「請求先アカウント」をプロジェクトに関連付ける
この無料トライアルの登録で、新しく「請求先アカウント」という名前(ものすごく紛らわしい名前)の請求先アカウントが作成され、33,813円がチャージされていました。
これを、プロジェクトに関連付けて、支払先として登録してあげます。
まず、Google Cloud Platform Console上で、プロジェクトを選択した状態で、左上の「メニュー(三本線)」ボタン→「お支払い」→「お支払設定」とクリックします。
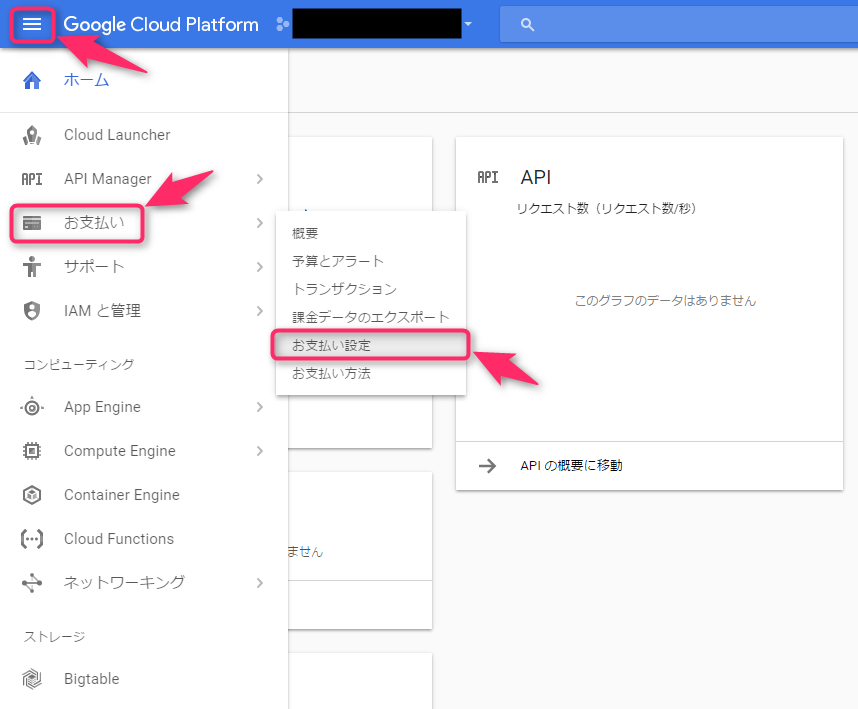
「請求先アカウントの設定」ポップアップで、「請求先アカウント」という名前の請求先を選択し、「アカウントを設定」をクリックして確定しました。
これで、BigQueryにデータを保存できるようになります(BigQueryの料金体系では、クエリの実行には無料枠があり、保存操作自体は無料の操作だが、保存したデータを保存し続けることに対する維持費に無料枠はなく有料なので、支払先の指定が必要、のはず)。
(補足)無料トライアルを使わない・使えない場合は
無料トライアルが使えない人の場合は、初めからGoogle Cloud Platformの左上の「メニュー(三本線)」ボタンから「お支払い」に進んで、請求先アカウントを作ることになるはずです。クレジットカードを登録しつつ、プロジェクトにその請求先アカウントを関連付けてみてください。
Google BigQuery:Google Cloud SDKをインストールする
これ以降は極力コンソールから作業をしたいので(記録もしやすいし)、Google Cloud SDKをインストールして作業します。
インストール手順はDocumentの「Cloud SDK のインストール | Cloud SDK のドキュメント | Google Cloud Platform」に記載されています。基本はコピペ実行です。
$ export CLOUD_SDK_REPO="cloud-sdk-$(lsb_release -c -s)" $ echo "deb https://packages.cloud.google.com/apt $CLOUD_SDK_REPO main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list $ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - $ sudo apt-get update && sudo apt-get install google-cloud-sdk $ gcloud init
Google BigQuery:Google Cloud SDKの利用
最後の「gcloud init」実行時に、「You must log in to continue. Would you like to log in (Y/n)?」と表示されるので、「Y」と入力した上で表示されたOAuth URLにブラウザでアクセスし、「許可」をクリックし、ブラウザ上で発行された認証用コードを、コンソールに表示された「Enter verification code:」にペーストしてEnterを押下しました。
プロジェクトの選択
「Pick cloud project to use」と表示されるので、今回使いたいプロジェクト名の左に表示された数字(自分は「3」)を入力しました(※[4] Create a new projectがあったので、ここで作ることもできた模様。支払い情報は・・・どうだろう)。
Google Compute Engineの設定
ここで、「API [compute_component] not enabled on project [****]. Would you like to enable and retry? (Y/n)?」と表示されてしまったので、「Y」を入力して有効化しました(この操作が終わるまで1,2分かかりました)。
さらに「Do you want to configure Google Compute Engine (https://cloud.google.com/compute) settings (Y/n)?」と表示されたので、ここでも「Y」を入力してみることに。
「If you do not specify a zone via a command line flag while working with Compute Engine resources, the default is assumed.」に対して以下の一覧が表示されたので、「[1] asia-east1-b」を選択してみました(参考:地域とゾーン | Compute Engine | Google Cloud Platform)。
[1] asia-east1-b
[2] asia-east1-a
[3] asia-east1-c
[4] asia-northeast1-c
[5] asia-northeast1-b
[6] asia-northeast1-a
[7] asia-southeast1-b
[8] asia-southeast1-a
[9] europe-west1-c
[10] europe-west1-d
[11] europe-west1-b
[12] us-central1-b
[13] us-central1-a
[14] us-central1-c
[15] us-central1-f
[16] us-east1-c
[17] us-east1-b
[18] us-east1-d
[19] us-west1-a
[20] us-west1-b
[21] Do not set default zone
Please enter numeric choice or text value (must exactly match list item):
ログイン状態を確認
「$ gcloud auth list」コマンドを実行して、認証済みアカウントが表示されることを確認しました。先ほどOAuth認証済みなのでばっちりです。
bqコマンドを使ってみる
次に、「$ bq ls」を実行してみると、「Credential creation complete. Now we will select a default project.」と表示されて、default projectをまた選べと言われるので、またプロジェクトを数字で選択しました。
参考:bq コマンドライン ツール | BigQuery のドキュメント | Google Cloud Platform
Google BigQuery:データセットを作成する(bq mkコマンド)
まず最初に、プロジェクトに対して「データセット」を作成します。RDBMSで言うところの「データベース」のように、複数のテーブルを格納できる場所、です。
今回は次のコマンドで、「log」という名前のデータセットを作成しました。
$ bq mk log
Google BigQuery:スキーマを用意する
ウェブサーバーのログファイルのスキーマを記載したJSONファイルを作成しておきました:
[
{ "name": "time", "type": "timestamp" },
{ "name": "host", "type": "string" },
{ "name": "forwardedfor", "type": "string" },
{ "name": "req", "type": "string" },
{ "name": "method", "type": "string" },
{ "name": "uri", "type": "string" },
{ "name": "protocol", "type": "string" },
{ "name": "status", "type": "integer" },
{ "name": "size", "type": "integer" },
{ "name": "reqsize", "type": "integer" },
{ "name": "referer", "type": "string" },
{ "name": "ua", "type": "string" },
{ "name": "vhost", "type": "string" },
{ "name": "reqtime", "type": "float" },
{ "name": "from_cache", "type": "string"},
{ "name": "is_mobile", "type": "string"},
{ "name": "uid_set", "type": "string"},
{ "name": "uid_got", "type": "string"}
{ "name": "time_local", "type": "string"}
]
※後述するNginxのログ設定をしてからここを設定することが普通かと思います。先にNginxの設定をして、スキーマを固めておくと良いかと思います
Google BigQuery:テーブルを作成する
「$ bq mk -t」コマンドを使って、作成したスキーマファイルを指定しつつ、テーブルを作成しました。
$ bq mk -t log.nginx_access_logs ./ltsv_format_schema.json
Nginx:アクセスログのフォーマットをLTSVにする
NginxやApacheのデフォルトのログフォーマット(combined)であっても、fluentdで読み込むことができないわけではありません。
しかし、デフォルトでは出力されない情報もログに出して、それをfluentdで読み込みたい、となると、項目の追加削除が簡単にできる「LTSV(Labeled TSV)」形式でログを出力するのがおすすめです。
基本は、Tab区切りなのですが、Tabで区切られたそれぞれの要素にラベルが付いており、ログの1行が「time_local:07/May/2017:05:16:30 +0900(タブ文字)host:111.222.333.444(タブ文字)forwardedfor:222.333.444.555(タブ文字)...」のようになります(IPアドレスはわざと存在しないものに;)。
これをNginxの設定ファイル中に、次の通り設定しました:
log_format ltsv "time_local:$time_local"
"\thost:$remote_addr"
"\tforwardedfor:$http_x_forwarded_for"
"\treq:$request"
"\tmethod:$request_method"
"\turi:$request_uri"
"\tprotocol:$server_protocol"
"\tstatus:$status"
"\tsize:$body_bytes_sent"
"\treqsize:$request_length"
"\treferer:$http_referer"
"\tua:$http_user_agent"
"\tvhost:$host"
"\treqtime:$request_time"
"\tfrom_cache:$sent_http_x_cache"
"\tis_mobile:$mobile"
"\tuid_set:$uid_set"
"\tuid_got:$uid_got"
;
※終盤4項目は別のNginxの設定に依存する設定なので、いきなり定義してもうまく動かないと思います。
そして、アクセスログの出力先を定義する「access_log」の部分を、以下のように記述しました(ltsvという定義したばかりのフォーマットを指定しているのがポイント)。
access_log /var/log/nginx/access.log.ltsv ltsv;
fluentd:fluent-plugin-bigqueryをインストールする
「fluentd」と言いつつ、使用したのは「td-agent」です。td-agentはTrasure Dataが配布している、fluentdをパッケージングしたもので、「Installing Fluentd Using deb Package」に書いてある次のコマンドで簡単にインストールできました。見た目上の名前は違いますが、使い方自体はfluentdのドキュメントを読めばOKです。
curl -L https://toolbelt.treasuredata.com/sh/install-ubuntu-xenial-td-agent2.sh | sh
※Xenial:Ubuntu 16.04のこと
現在インストール済のプラグインの確認は、「$ td-agent-gem list -l」。
今回は、「$ sudo td-agent-gem install fluent-plugin-bigquery」で、fluentdからBigQueryに転送するためのプラグインをインストールしました。
※このプラグインのページはこちら:https://github.com/kaizenplatform/fluent-plugin-bigquery
fluentd / Google BigQuery:サービスアカウントの作成
続いて、fluent-plugin-bigqueryがBigQuery APIの認証を通過するために必要な「サービスアカウント」の発行作業を行います。
再びGoogle Cloud Platform Consoleを開いて、「メニュー(三本線)」から「API Manager」を開き、「認証情報」を開きます。
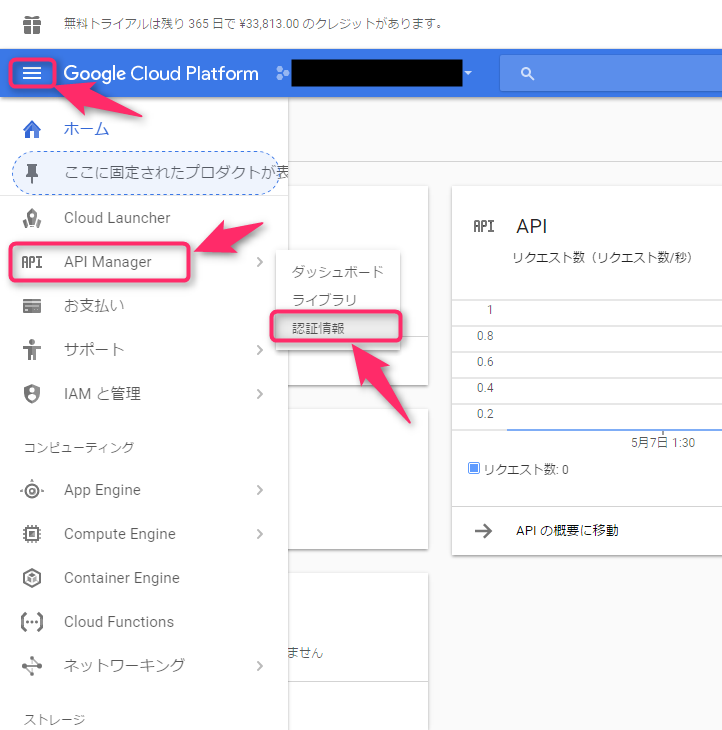
すると、次のポップアップが表示されるので、「認証情報を作成」の「サービスアカウントキー」をクリックします。

API
認証情報
API へのアクセスには認証情報が必要です。使用する API を有効化し、必要な認証情報を作成してください。API に応じて、API キー、サービス アカウント、または OAuth 2.0 クライアント ID が必要です。詳しくは、API ドキュメントをご覧ください。
[認証情報を作成]
- APIキー
シンプルAPIキーを使用してプロジェクトを識別し、割り当てとアクセスを確認します- OAuth クライアントID
ユーザーのデータにアクセスできるようにユーザーの同意をリクエストします- サービスアカウントキー
ロボットアカウントによるサーバー間でのアプリレベルの認証を有効にします- ウィザードで選択
使用する認証情報の種類を決定するため、いくつかの質問をします
「サービスアカウントキーの作成」画面が開いたら、まず「サービスアカウント」で「新しいサービスアカウント」を選択します。
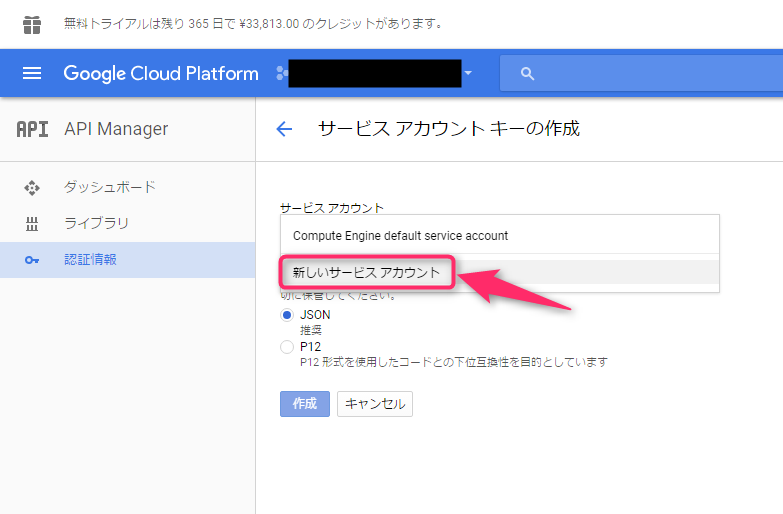
そうしたら、「サービスアカウント名(fluent-plugin-bigquery)」と「役割(難しい。今回この時点では「BigQuery 管理者」を選択)」を入力して、「キーのタイプ」に「JSON」を選択して、「作成」をクリックしました。

「新しい秘密鍵」ポップアップが表示されたら、「.json」ファイルを保存します。

fluentd:fluentdの設定をする
後は、fluentd-plugin-bigqueryを使うように、fluentd(td-agent)の設定ファイルを変更します。この際、先ほど保存した.jsonファイルの中身を開いて、「private_key」と「client_email」の部分を、「json_key」の設定にコピーしてあげます(.jsonには他にもいろいろ記載されているが、この2つだけでOK)。
<match bq.log.nginx_access_logs>
@type bigquery
method insert
auth_method json_key
json_key { "private_key": "-----BEGIN PRIVATE KEY-----\n...\n-----END PRIVATE KEY-----\n", "client_email": "fluent-plugin-bigquery@project-id.iam.gserviceaccount.com" }
project project-id
dataset log
table nginx_access_logs
time_format %s
time_field time
schema [
{ "name": "time", "type": "timestamp" },
{ "name": "host", "type": "string" },
{ "name": "forwardedfor", "type": "string" },
{ "name": "req", "type": "string" },
{ "name": "method", "type": "string" },
{ "name": "uri", "type": "string" },
{ "name": "protocol", "type": "string" },
{ "name": "status", "type": "integer" },
{ "name": "size", "type": "integer" },
{ "name": "reqsize", "type": "integer" },
{ "name": "referer", "type": "string" },
{ "name": "ua", "type": "string" },
{ "name": "vhost", "type": "string" },
{ "name": "reqtime", "type": "float" },
{ "name": "from_cache", "type": "string"},
{ "name": "is_mobile", "type": "string"},
{ "name": "uid_set", "type": "string"},
{ "name": "uid_got", "type": "string"}
]
</match>
また、LTSV形式で書き出されたNginxのログをfluentdが吸い上げる側の設定として、以下を追加します。
<source> type tail path /var/log/nginx/access.log.ltsv format ltsv keep_time_key time_key time_local time_format %d/%b/%Y:%H:%M:%S %z tag bq.log.nginx_access_logs pos_file /var/log/td-agent/nginx_access.log.ltsv.pos </source>
fluentd:fluentdの再起動
ここで、「$ sudo systemctl restart td-agent.service」で再起動し、設定を反映させました。
結果:BigQueryで分析可能に
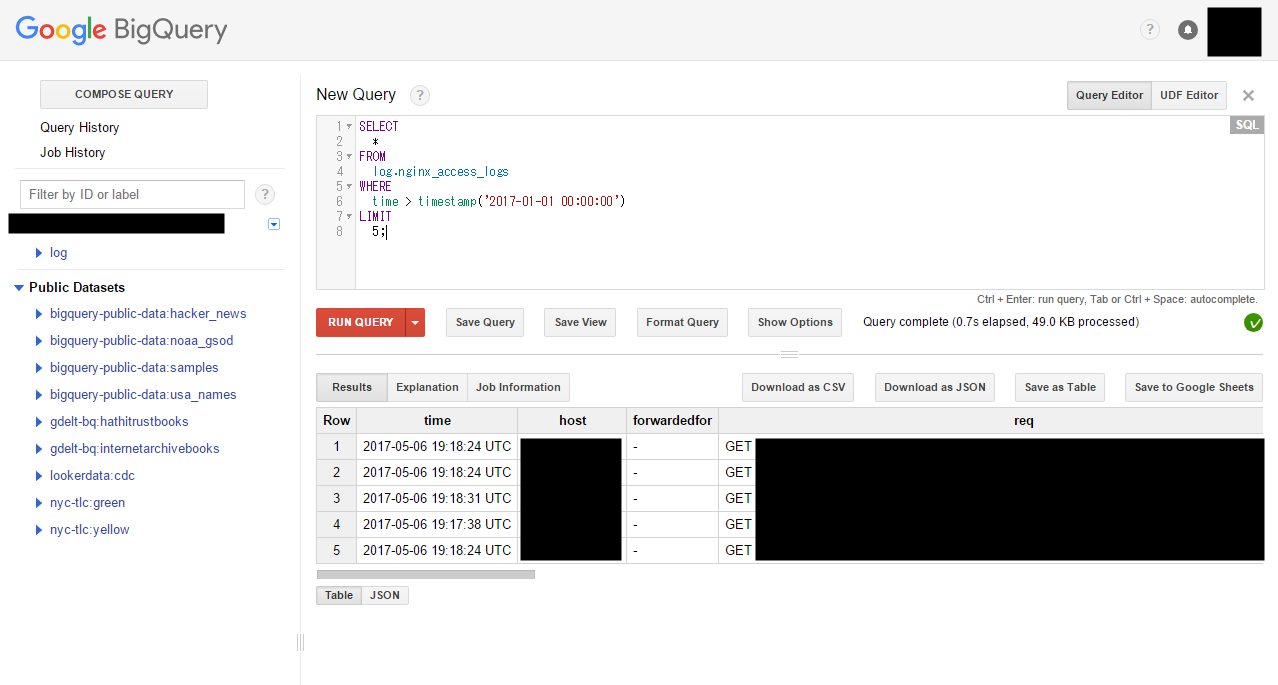
こうしてすいすいNginxのログはBigQueryにアップロードされ、Google BigQueryのConsoleにて、SQLを用いてアクセスログを分析できるようになりました。
次の画像は、動作確認中のクエリ:
参考
参考URL。
fluentd / BigQuery
- いまさらだけど、Nginx が出力したアクセスログ(ltsv形式)を fluentd 経由で BigQuery に送ってみたよ - えいのうにっき
- nginx のアクセスログを fluentd 経由で BigQuery に投げてみる by a-know · Pull Request #54 · a-know/a-know-home-server
- FluentdでGoogle BigQueryにログを挿入してクエリを実行する - Qiita
- kaizenplatform/fluent-plugin-bigquery
- fluentd/inject.rb at master · fluent/fluentd
- Real-time logs analysis using Fluentd and BigQuery | ソリューション | Google Cloud Platform
Nginx / TLSV / fluentd
- Labeled Tab-separated Values (LTSV)
- いまさら fluentd をはじめてみたLTSV なにそれ美味しいの?、その2 - Qiita
- nginx のアクセスログを LTSV にする - Qiita
- Alphabetical index of variables
Nginx log_format
- ISO 8601 - Wikipedia
- Logging and Monitoring | NGINX
- Module ngx_http_upstream_module
- Nginxからトラッキング用のCookieを設定する - Qiita
- Module ngx_http_core_module
Nginx キャッシュ設定
fluentd
- fluent-plugin-multiprocessと戯れた話 - Qiita(「USR1シグナルについて」の部分)
- td-agent(fluentd)のposファイルの作成タイミングとかその他もろもろもメモ - tweeeetyのぶろぐ的めも
- Plugin Management | Fluentd
- BufferedOutput pluginの代表的なoptionについて - Qiita
BigQuery
- Google BigQuery Console
- bq コマンドライン ツール | BigQuery のドキュメント | Google Cloud Platform
- 地域とゾーン | Compute Engine | Google Cloud Platform
- 料金 | BigQuery のドキュメント | Google Cloud Platform
- BigQuery へのデータのストリーミング | BigQuery のドキュメント | Google Cloud Platform
- Bigquery | 日付・時間系のクエリまとめ ( query reference 日本語訳 ) - Qiita
Google Cloud Platform
追記:ログファイルのファイルサイズが巨大化してしまってディスク容量を圧迫(+速度低下?/性能低下?)
ログファイル「/var/log/nginx/access.log.ltsv」が、123GBという巨大ファイルになってしまっていることに気が付きました。
ファイル名が「.log」で終わらないために、「/etc/logrotate.d/nginx」で指定されていたlog rotateの設定から外れてしまっていたようです。
そこで、「/var/log/nginx/*.log {」で始まっていたその設定ファイルを「/var/log/nginx/*.log /var/log/nginx/*.log.ltsv {」に変更し、「$ sudo /usr/sbin/logrotate /etc/logrotate.conf」で反映しました。
また、巨大化しすぎていたそのファイルを一旦「sudo rm /var/log/nginx/access.log.ltsv」で削除しました。そして、これだけでは「df -h」の空き容量が増えておらず、あれ?と思ったので、使っていたであろうnginxのプロセスを再起動させるため、「$ sudo systemctl restart nginx.service」を実行しました。すると、空き容量が一気に大きくなりました。
スポンサーリンク
スポンサーリンク