スポンサーリンク
LifeStuffは、ユーザのデータを暗号化してP2Pネットワーク上に保存するサービスです。このとき、「ユーザが保存するデータの75%から90%は重複している」という性質を利用し、同じデータを保存しないようにして、ストレージの節約を行います。しかし、誰かが暗号化して保存したファイルと、自分が暗号化して保存しようとしているファイルが「同じである」と、一体どのようにして見分けられるというのでしょうか(次画像・画像の説明は本文にて)。
↓素朴なやり方ではうまく重複排除できない↓

今回は、この問題を解決するためにLifeStuffが利用している技術Self-Encryptionについて、そのアイディアとエッセンスを紹介したいと思います。
私はこの方式を知ったとき「なるほど!」と思いました。この説明を読んだ方にも「なるほど!」と思っていただけると嬉しいです。
LifeStuff社の情報に、そうなった理由やどうしてうまく行くのか、どうすればいいのか、などの背景分析を独自に加えて解説していきます。
目次
スポンサーリンク
素朴な実装方法:あなたならどう設計しますか?
まずはじめに、素朴な「暗号化して保存する仕組み」を考えてみます。すると、どこが難しいのかが分かると思います。
使って良い道具3つ:「DHT」「ハッシュ関数」「暗号化・復号化関数」
LifeStuffはDHTと呼ばれる技術を利用しています。DHTを利用すると、P2Pネットワーク上に「keyとvalueのペア」を保存したり、「key」に対応する「value」を取得することができます(連想配列)。これを中心にシステムを構築します。
また、ハッシュ関数(Hash)と暗号化・復号化関数(Encrypt・Decrypt)が用意されているとします。
(それぞれ具体的には、DHTとしてKademlia、ハッシュ関数としてSHA512、共通鍵暗号方式としてAES256 ECBモード、を利用しています(2008年時点)。)
素朴な実装方法の「保存」
この機能を利用すると、次のような素朴なシステムが設計できます。
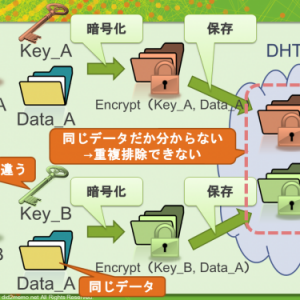
1.暗号化する
まず「ユーザA」は、保存したいデータ「Data_A」を、暗号化キー「Key_A」で暗号化します。その暗号化した結果のデータは「Encrypt(Key_A, Data_A)」と書けます。
2.DHTに保存する
そうしたら、この暗号化結果「Encrypt(key_A, Data_A)」をDHTへ保存します。
先ほど説明したように、key-valueペアを保存するので(※ここの"key"と暗号化鍵という意味の"Key_A"は無関係です)、valueを「Encrypt(Key_A, Data_A)」、keyをvalueのハッシュ値「Hash(Encrypt(key_A, Data_A))」として保存します。

このとき、取得するときに困らないように、「Data_Aの名前『DataName_A』は『key:Hash(Encrypt(Key_A, Data_A))』に保存しておいたぞ」、という対応関係を覚えておきます。
取得したいときは
「DataName_A」のデータ、つまり「Data_A」を取得したい時はどうするかというと、先ほどの対応関係を参照して、keyに「Hash(Encrypt(Key_A, Data_A))」を設定して、DHTにクエリを投げ込むとvalueである「Encrypt(Key_A, Data_A)」が取得できます。
もちろんユーザAは自分の暗号化キーKey_Aは知っているので、これを復号化することで「Data_A」が取得できます。
めでたしめでたし、なのでしょうか。
これでは重複排除機能が導入できない!
実はこのままでは、同じデータを保存したときに重複を検出して排除する、という仕組みが実現できないのです。もしこれができないと、LifeStuffはストレージサイズを節約できずに大変なことになると予想されます。では、どうして重複を検出できないのでしょうか、説明します。
どうして重複排除機能を導入できないのか
さきほどユーザAさんは、「Data_A」を保存した結果、DHTには「Encrypt(Key_A, Data_A)」というvalueが保存されました。
では、「ユーザB」さんが、同じ「Data_A」を保存するときはどんなvalueが保存されるでしょうか。
ユーザBさんはユーザAさんとは違う暗号化鍵Key_Bを使って暗号化するはずなので、保存されるvalueは「Encrypt(Key_B, Data_A」となるはずです。
さて、同じデータ(Data_A)であっても、暗号化鍵が違えば、暗号化結果は全く違います。つまり、ユーザAさんとユーザBさんは全く同じデータ「Data_A」を保存したのにもかかわらず、お互いの暗号化鍵が異なるために、「Encrypt(Key_A, Data_A)」と「Encrypt(Key_B, Data_A)」という全く違うvalueをDHTに格納してしまったのです。
つまり、保存されたvalueを見比べても、同じファイルなのかどうなのか検出できないのです。
これでは、困ってしまいます。また、たとえ同じファイルを暗号化したものだと分かったとしても、ユーザAさんはユーザAさん用のvalueしか復号化できませんし、ユーザBさんはユーザBさん用のvalueしか復号化できませんから、どちらかのvalueを削除して重複を排除するわけにはいかないのです。
このように、ユーザAさんとユーザBさんが違う鍵を使うせいで、重複を排除しようにも、どうにもならないのです。
同じ鍵を使う!・・・??
そうすると、「ユーザAさんとユーザBさんが同じ鍵を使わないといけない」気がします。しかし、「そんなことしたらセキュリティ的にダメだろ」と思う人が多いかと思います。

しかし、LifeStuffは、まさに暗号化鍵をユーザ間で共有してしまいます、とても賢い方法を利用して。
誰と誰が同じ鍵を使えばいいのか
今回の例では、ユーザAさんとユーザBさんが同じ鍵を知っていればいいことになります。しかし、別のユーザであるユーザCさんには知られたくありません。
これを冷静に分析して整理してみると、Data_A用の鍵が満たすべき性質は、「Data_Aのファイルを持っている人が知っている」かつ「Data_Aのファイルを持っていない人は知らない」です。
こんな不思議な鍵を使うことに成功してしまうのがLifeStuffの言うところのSelf-Encryptionという方式です。
Self-Encryption
ここまででアイディアに至るまでの考え方を示したので、もう勘の良い人はどんな方法か分かったかもしれませんが、いよいよSelf-Encryptionの概要を説明します(※LifeStuffではより高度な方法を使っているとされていますが、基本的にはここで紹介する方式を利用しています。また、重複排除自体に貢献の少ない部分については「中級編」にて後述および省略します)。
データのハッシュ値で暗号化する
Self-Encryptionでは、暗号化したいデータをそのデータ自身のハッシュ値を鍵として暗号化します。
つまり、先ほどの書き方で書くと、「Data_A」は、「Encrypt(Hash(Data_A), Data_A)」に暗号化されてDHTに保存されます。
ここで注目すべきは、暗号化されたデータ「Encrypt(Hash(Data_A), Data_A)」には、ユーザの入力が一切含まれない(no user input)という点です。
そして、この暗号化されたデータを復号化できるのは、もともとのデータ(Data_A)から暗号化キー(Hash(Data_A))を作ることができる人だけ、つまりデータの持ち主にしか復号化できないという状態が実現できているのです。

どうでしょうか、「なるほど!」と思っていただけたでしょうか。
LifeStuffでのSelf-Encryption利用法
LifeStuffでは、DHTに保存するkey-valueペアとして、valueは暗号化データ「Encrypt(Hash(Data_A), Data_A)」、keyはvalueのハッシュ値「Hash(Encrypt(Hash(Data_A), Data_A))」を採用しています。
しかしこのとき、key「Hash(Encrypt(Hash(Data_A), Data_A))」に対して既にデータが保存済みでないかをチェックしてから保存します。つまり、データを保存してから重複を除去するのではなく、あらかじめ重複してしまわないかチェックしてから保存することで、重複の発生を排除します。
LifeStuffのメタデータ管理法
データを保存したユーザは、「どんなファイル」を「どんなkeyに」保存したかという対応付け(DataMapと呼ばれる)をメタデータとして、もう一度暗号化後、DHTへ保存します。つまり、このメタデータをMaidSafe社が管理することさえないわけです。なので、メタデータを集めて誰と誰が同じデータを持っているかを分析することすらMaidSafe社はできません。
このメタデータを束ねたものが、ユーザの保存したデータの一覧となります、この一覧をDHTへ保存するだけですが、valueは「Encrypt((ユーザ名とパスワードから生成した鍵),(DataMapを束ねたもの))」となり、keyは「ユーザ名・ PIN番号・とある乱数」から生成した値となります。なので、このメタデータ(ユーザAがどんなデータを保存したのかという情報)は、ユーザ本人しか取得、復号化できない保存形式となります。
ここまでのまとめ
このように、LifeStuff(が利用するMaidSafe-DHT)は、暗号化と重複排除(deduplication)の両立を実現しています。
同様の方法は無限ストレージを提供するbitcasa社も利用しています。ただし、bitcasaはサーバ上に保存している、つまりP2Pではなく、だいぶセキュリティに関する事情が異なっている点に注意してください(bitcasa社を信じるかどうか、など)。
解説動画
この方式などを含めたLifeStuff(MaidSafe)の技術について、この動画で知ることができます。
中級編へ
実は、LifeStuffでは、Self-Encryptionを行うとき、「Encrypt(Hash(Data_A)),Data_A)」 のように丸ごと保存するのではなく、データを細切れにして細切れになったデータの一つ一つをチャンクと呼び、実際はチャンクごとに保存しています。
大きいファイルも小さいファイルもチャンクに分割することでデータサイズを扱いやすくする意味も当然あるとは思いますが、実はチャンクに分割することで、セキュリティを大幅に向上させる仕組みを導入しており、暗号化方式のもう一つの売りにしています。これについては、また近く解説したいと思います。
感想
解説していると、またいろいろ新しいことが見えてきました。こういう場合、セキュリティはどうなんだろう、こういう仕組みにしたらセキュリティは弱くなってしまうのだろうか、実際にはさらにどんな工夫をしているのだろうと考えてみるととても面白いと思います。その際は、これがあくまでエッセンスの解説であることをお忘れ無く。
スポンサーリンク
2012年9月9日(日) 10:53
(from @nahi) Convergent encryptionについてはこんな議論があります: https://tahoe-lafs.org/hacktahoelafs/drew_perttula.html
2012年9月10日(月) 17:08
>なひさん
情報提供ありがとうございます。リンク先を読ませていただきました。いろいろな攻撃・対策について考察するきっかけになりました。
confirmation-of-a-file attackの可能性は気がついていたのですが、learn-the-remaining-information attackには気がつきませんでした。
以下、感想となります。
具体的なアプリケーションとしてLifeStuffを想定すると、"Defense Against Both Attacks"で紹介されているadded_secretを追加する方法では、個人のユーザ内の重複の排除は可能ですが、ユーザをまたぐ重複排除には利用しにくく、導入が難しそうです。また、アップロードするファイルのエントロピーについて考えるのも一般ユーザにとっては困難すぎるように思いました。
ただし、convergent encryptionの有効・無効を選択できる、というのはLifeStuffでも有効でかつ簡単な対処法であるように感じました。しかしながら、無効を選択したユーザに要求する容量の増加が大きすぎる可能性と、有効・無効の選択や、一般ユーザへの有効・無効が選択可能である理由の説明がやはり難しいというところまで考えると、やっかいに感じました。
このように、P2Pだからこそ対応が困難、という面がある一方で、P2Pならではの対処法も考えてみると、本質的に「すでに同じファイルがアップロード済みである」ということがバレなければよいので、「データ保存時、ファイルが重複しているかのチェックを手元で行わず、とにかくアップロードする(既にアップロード済みのファイルだったのか区別ができないようにするため)」と「データ取得時、自分が保存したデータしか取得できない(ファイルをアップロードせずに、そのファイルがDHT上に存在するかチェックできないようにするため)」の2点を実現できればよさそうです。ただし、前者については、自分自身が保存先マシンだと区別が付いてしまうう可能性があったり、後者についてはどのように実現すれば突破されないのかが問題として残ってしまいました。
実際にLifeStuffがどのように対策しているのかが気になるところです。
2013年11月16日(土) 07:36
I would like to say I am all new to blogging and actually liked your site. You very have great articles. Cheers for sharing your web-site. %KW%
Emma http://antonxx93.500mb.net/user/exazybixwgj/