スポンサーリンク
PCで突然「ハードディスクの問題が検出されました」と表示されたので、それについて書いておきます。
(英語だと「Windows detected a hard disk problem」なので、海外サイト検索時の参考にしてください)
目次
スポンサーリンク
エラー表示
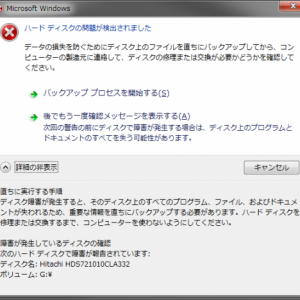
表示されたのは、次のような文章です(Windows 7 Professional)。

Windowsからのエラー
ハードディスクの問題が検出されました。
データの損失を防ぐためにディスク上のファイルを直ちにバックアップしてから、コンピューターの製造元に連絡して、ディスクの修理または交換が必要かどうかを確認してください。
- バックアッププロセスを開始する
- 後でもう一度確認メッセージを表示する
次回の警告の前にディスクで障害が発生する場合は、ディスク上のプログラムとドキュメントのすべてを失う可能性があります。
直ちに実行する手順
ディスク障害が発生すると、そのディスク上の全てのプログラム、ファイル、およびドキュメントが失われるため、重要な情報を直ちにバックアップする必要があります。ハードディスクを修理または交換するまで、コンピューターを使わないようにしてください。
障害が発生しているディスクの確認
次のハードディスクでしょうが意が報告されています:
ディスク名:Hitachi HDS721010CLA332
ボリューム:G:\
ラピッド・ストレージ・テクノロジーの表示
HDDユーティリティ「インテル ラピッド・ストレージ・テクノロジー」では、次のように表示されました。
現在のステータス
システムは1つ以上のイベントを通知しているので、データに問題がある可能性があります。
詳細は以下を参照してください。
ポート - 2のディスク:危険
さらに該当HDDをクリックして詳細を表示した結果がこれです。
ステータス:危険 ディスクを正常にリセット
利用状況:使用可能
サイズ:953,869 MB
シリアル番号:JP...
モデル:Hitachi HDS721010CLA332
ファームウェア:JP4OA39C
CrystalDiskInfo 5.3.0によるS.M.A.R.T.の表示
あまりS.M.A.R.T.を気にしないタイプですが、S.M.A.R.T.を見るための推奨ツールと書いてあったCrystalDiskInfoで値を確認してみました。すると、かなりさんざんな状態でした。
----------------------------------------------------------------------------
(2) Hitachi HDS721010CLA332
----------------------------------------------------------------------------
Model : Hitachi HDS721010CLA332
Firmware : JP4OA39C
Serial Number : **************
Disk Size : 1000.2 GB (8.4/137.4/1000.2)
Buffer Size : 29999 KB
Queue Depth : 32
# of Sectors : 1953525168
Rotation Rate : 7200 RPM
Interface : Serial ATA
Major Version : ATA8-ACS
Minor Version : ATA8-ACS version 4
Transfer Mode : SATA/300
Power On Hours : 18134 時間
Power On Count : 538 回
Temparature : 29 C (84 F)
Health Status : 注意
Features : S.M.A.R.T., APM, AAM, 48bit LBA, NCQ
APM Level : 0000h [OFF]
AAM Level : 80FEh [OFF]
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
01 _86 _86 _16 00000040005D リードエラーレート
02 133 133 _54 000000000068 スループットパフォーマンス
03 117 117 _24 0006014C013A スピンアップ時間
04 100 100 __0 0000000008CB スタート/ストップ回数
05 100 100 __5 000000000083 代替処理済のセクタ数
07 100 100 _67 000000000000 シークエラーレート
08 130 130 _20 000000000023 シークタイムパフォーマンス
09 _98 _98 __0 0000000046D6 使用時間
0A 100 100 _60 000000000000 スピンアップ再試行回数
0C 100 100 __0 00000000021A 電源投入回数
C0 _98 _98 __0 000000000AB6 電源断による磁気ヘッド退避回数
C1 _98 _98 __0 000000000AB6 ロード/アンロードサイクル回数
C2 206 206 __0 002A000A001D 温度
C4 100 100 __0 00000000008A セクタ代替処理発生回数
C5 100 100 __0 000000000006 代替処理保留中のセクタ数
C6 100 100 __0 000000000001 回復不可能セクタ数
C7 200 200 __0 000000000000 UltraDMA CRC エラー数
特に強調表示した「代替処理済のセクタ数」「代替処理保留中のセクタ数」「回復不可能セクタ数」が注意を表す黄色信号表示になっており、実際の値(RawValues)の部分が確かにかなりひどいことになっていました(RawValuesのところが0(000000000000)でない時点で良くないのに、数値が大きすぎる)。
「ハードディスクの問題が検出されました」の原因
いろいろ同じ症状の人を探してみた結果、Wiondowsはこの「S.M.A.R.T.」の異常値を検出して警告メッセージを表示してくれたようでした。値が悪すぎたんですね。
他のHDDもあぶない感じだった
他のHDDも値が多少ましなものの、「注意」と表示されており、交換しようと思いました。
とりあえずの対策
とりあえず、まだドライブにはアクセスできるようだったので、急いで空のHDDに丸ごとコピーを開始しました(結局終了は20時間後)。以前HDDが故障したとき、最後の最後再起動がとどめになることがあると知ったので、間違っても再起動してしまわないように気を付けつつ、急いでコピーを始めました。
HDDの買い替え
というわけで、突然故障しなかっただけマシでした。しかし、いつ使えなくなるか分からないので、交換用に新しいHDDを2台購入しました。話題になっているように値上がりが進んでいましたが、まだ十分安いと思える範囲で良かったです。
参考
追記(2013-01-22)
上記のエラーから24時間経たないうちに、CrystalDiskInfoの判定が「注意」から「異常」に変化しました。
「異常」となったのは「リードエラーレート」です。
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
01 _15 _15 _16 00007F07FFFF リードエラーレート
02 133 133 _54 000000000068 スループットパフォーマンス
03 117 117 _24 0006014C013A スピンアップ時間
04 100 100 __0 0000000008CB スタート/ストップ回数
05 100 100 __5 000000000096 代替処理済のセクタ数
07 100 100 _67 000000000000 シークエラーレート
08 130 130 _20 000000000023 シークタイムパフォーマンス
09 _98 _98 __0 0000000046ED 使用時間
0A 100 100 _60 000000000000 スピンアップ再試行回数
0C 100 100 __0 00000000021A 電源投入回数
C0 _98 _98 __0 000000000AB6 電源断による磁気ヘッド退避回数
C1 _98 _98 __0 000000000AB6 ロード/アンロードサイクル回数
C2 206 206 __0 002A000A001D 温度
C4 100 100 __0 00000000009D セクタ代替処理発生回数
C5 100 100 __0 000000000007 代替処理保留中のセクタ数
C6 100 100 __0 000000000000 回復不可能セクタ数
C7 200 200 __0 000000000000 UltraDMA CRC エラー数
「回復不可能セクタ数」は減少したものの、「代替処理済みのセクタ数」は増加していました。ただ、今のところはまだデータを読み出せる状態です。
スポンサーリンク
スポンサーリンク